The SQL of trust in a NoSQL world
Observations on how, and why, certain aspects of SQL seem to be getting incorporated into some NoSQL products
From the movie Meet the Parents, the “circle of trust” quote is amongst other things, used to infer that you can only really be part of the family once you are inside “the circle of trust”. NoSQL vendors are desperate to attain a greater de facto acceptance as heavyweights and household names to be relied on in the broader software development community, and especially in the lucrative enterprise space. To this end, there appears to be a courting of a few of the battle hardened supporters from the RDBMS world with the lure of “some sort of familiarity” to their current known world in order to help try and break into this circle of trust. One such area of familiarity is SQL, and it is interesting to observe the different degrees to which some NoSQL vendors have gone in adapting their respective querying languages to cater for this fact. Now let me be clear that there is absolutely nothing wrong with this approach – provided of course it does not completely skew and dumb down the original benefits of the underlying datastore in question.
It should come as no surprise that when it comes to data, the vast majority of developers today (yes even in 2015) still think in structured RDBMS terms, and when it comes to querying data – SQL is probably the most prominent query language still out there. This simply stems from the fact that NoSQL databases are still relatively young compared to their RDBMS counterparts which have been around for a lot longer.
N*SQL (No/NewSQL) databases are by definition, going to be very different to RDBMS and querying the data from them will more than likely be different as well. So is there any common ground here, specifically is it possible for a structured query language like SQL to easily translate or morph to being used in an unstructured context as well? Should we even trust this approach? SQL vs NoSQL? Time for some examples …
Setting the scene – an RDBMS example
Suppose we are modelling an ordering system where we have ORDERS, consisting of ORDERLINES linked to PRODUCTS as shown in the diagram below.

Lets also assume we want to ask two questions of our data relating to the purchases of Raspberry Pi’s (product ID P4). We could write some SQL queries as shown below to query this data:

Now not every NoSQL database is going to have some form of SQL sympathy built into its query language, and there are simply too many of them out there for us to compare them all. I shall therefore pick two that I have actively worked with to use as examples for my purposes. Lets see how Cassandra and Neo4j deal with the modelling and querying of this data with their respective query languages.
Cassandra and CQL
Cassandra falls into the column family NoSQL camp with its “semi structured” format and is presently heavily pushing CQL (The Cassandra Query Language) as the recommended way of interacting with it’s underlying datastore.
“Cassandra Query Language (CQL) is the default and primary interface into the Cassandra DBMS. Using CQL is similar to using SQL (Structured Query Language). CQL and SQL share the same abstract idea of a table constructed of columns and rows. The main difference from SQL is that Cassandra does not support joins or subqueries” - www.datastax.com/documentation/ cassandra/2.1/cassandra/cql.html
For this example I am going to work backwards, i.e. first show you the CQL query statements which result in the same answers to the SQL queries used in the RDBMS example above, and then pick up on a few related discussion points.
-- Num Raspberry Pi's bought by each customer:
SELECT * FROM CustPurchByProduct
WHERE productId = 'P4'
-- Total number of distinct users who bought Raspberry Pi's
SELECT COUNT(*) FROM CustPurchByProduct
WHERE productId = 'P4'
Syntax looks quite similar to SQL, albeit the query seems scarily simple. So where are those SQL joins, what’s going on? As per the official philosophy, Cassandra does not really do joins, rather you are actively encouraged to denormalize your data (i.e. don’t be afraid to write data multiple times if necessary) to answer different questions. In this case, you might decide to model your domain something as follows:
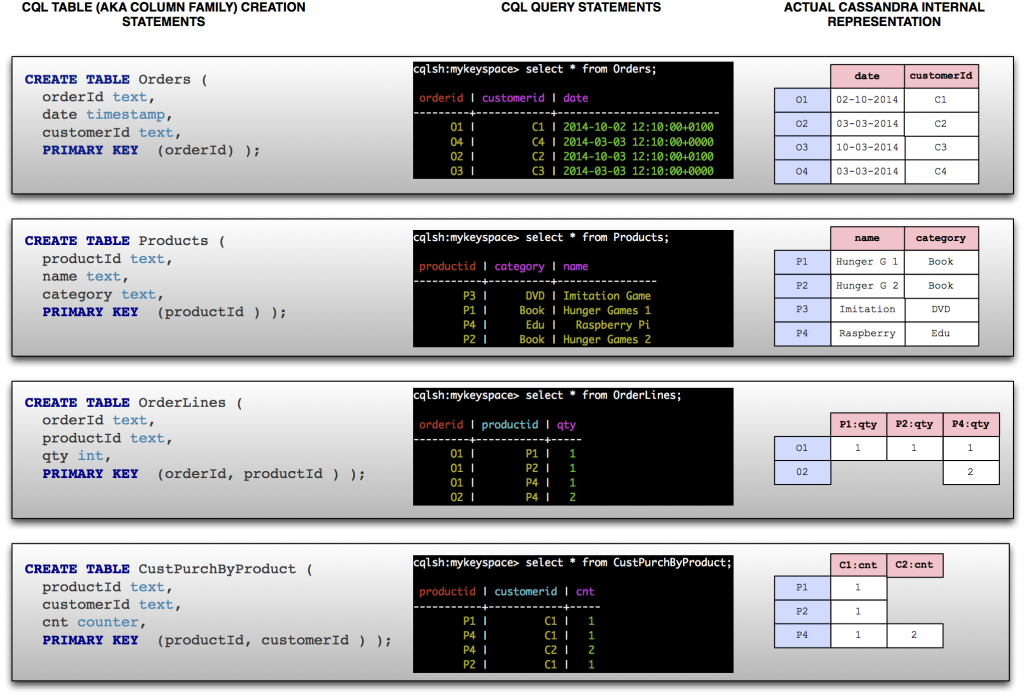
Each table is an island
OK, Cassandra does not do joins, and in this case we can see that a whole separate denormalized table (aka column-family in Cassandra) CustPurchByProduct was created to answer the two core questions posed.
So in this case, the comparison is simple, the concept of SQL joins simply does not exist. You should never really expect to see any SQL join like syntax in CQL statements, and by implication, no foreign key references either – it simply does not compute in Cassandra.
The 3 legged table
Leaving the joins and foreign keys aside, via the CQL shell (similar to SQL shell type programs), we gain some tabular insight into our data. The CQL CREATE and SELECT statements relating to Orders and Products column families seem to map very similarly to their RDBMS counterpart – tables, so far so good.
Lets however take a closer look at OrderLines. Firstly, what is interesting to note is that even though the CQL SELECT queries appear to give the impression of bringing back four traditional RDBMS style rows with three columns (orderId, productId and qty), under the covers the story is quite different. The internal representation of the OrderLines column family actually has two Cassandra partitions (think rows) with a variable number of columns. You can think of a partition (and in fact this is how the underlying storage engine would represent it) as a very wide row in an RDBMS; one that has no fixed set of columns, but rather the columns are dynamically created based on the table definition, and the actual data stored. In our example P1:qty, P2:qty and P4:qty are the effective column names, with the only value stored as a table cell being the qty itself. This is an example of Cassandra ensuring that CQL can use the full potential of the underlying storage engine – one of Cassandra’s key strengths, whilst at the same time, giving users an easier way of defining and visualising the data, closer to the way in which a more traditional RDBMS developer might expect to see/reason about it.
This RDBMS column mismatch phenomenon is also highlighted when looking at the CQL CREATE statement for OrderLines and CustPurchByProduct. Although they look very similar to SQL CREATE statements, they do not translate into a 1-to-1 mapping of physical column names in the traditional RDBMS. In this case a pivot like transformation is performed on the fly, both when the data is initially presented/inserted, as well as queried via CQL. This way CQL ensures that the transformation between what is logically defined and presented to the user, and the physical representation, is kept in sync for both the CREATE and SELECT statements, so ultimately, the two move together.
SideNote: The OrderLines column family is actually a little thin. In reality, this column family would more than likely have a few extra columns, something along the lines of what is shown in the diagram below. Again, this is because there are no joins and Cassandra actively encourages you to denormalize your data. For the purposes of this blog entry however, it has deliberately been kept thin to allow for an easier comparison with the alternative options. CustPurchByProduct probably falls into the same category too.
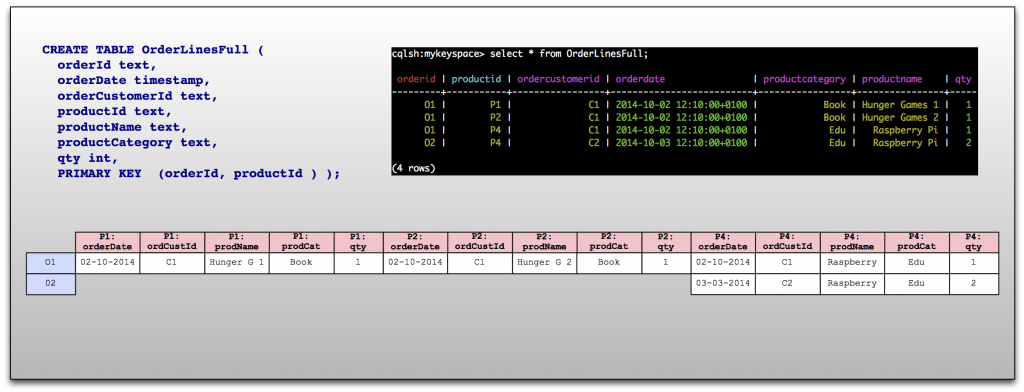
To be, or not to be - that is the question
Another thing which tends to confuse newcomers to Cassandra, is that a PRIMARY KEY definition in CQL, is not treated in the same way as a that for an RDBMS.
Firstly lets examine this from the perspective of the data model and storage perspective. If you look closely at the CQL CREATE statement for the CustPurchByProduct column family, and what this physically translates to under the covers, you will see that the first part of the SQL looking compound primary key (productId) was used as the row key (also referred to as a partition key in Cassandra). The remaining column customerId (in Cassandra terminology also referred to as a clustering key) actually got its value‘s absorbed into the various column headings itself (C1:cnt, C2:cnt)! Not quite what you might have been expecting.
Secondly, you would expect a primary key to ensure that you only have one unique record in the database for a given key, can we at least rely on this? The answer is Yes but… Cassandra will indeed ensure that there is only one reference to a combination of a primary key, however Cassandra tends to treat both its INSERT and UPDATE statements as ‘Add or update’. In other words, having already inserted a record with primary key X, you could call that exact same statement again and it would not throw a “Primary Key Already Exists” type exception, rather, it would simply update the existing row. Likewise you could call UPDATE with data which does not exist and it would merely insert it the first time and update it thereafter.
The point here is that a PRIMARY KEY as used in CQL is not an exact 1-to-1 logical mapping to its counterpart used in SQL.
Cassandra wrap up …
There is much more which could be said about the specifics of Cassandra data modelling, however as the point of this particular blog post is more to highlight how NoSQL query languages translate/compare to SQL, and not what the merits and demerits of particular stores and data modelling approaches are, we shall leave this example here. Perhaps a dedicated blog on specific DB comparisons could be next on the cards. In any case, we now move on to look at Neo4j.
Neo4j and Cypher
Neo4j is a graph database, where its sweet spot is getting answers about highly connected data. With a graph, you tend not so much to query vast swathes of its total structure, as you do start somewhere and then traverse it, gathering info along the way. Cypher has evolved as Neo4j’s humane graph query language.
“Cypher is inspired by a number of different approaches and builds upon established practices for expressive querying. Most of the keywords like WHERE and ORDER BY are inspired by SQL. Pattern matching borrows expression approaches from SPARQL…. Cypher borrows it structure from SQL — queries are built up using various clauses.” – http://neo4j.com/docs/stable/cypher-introduction.html
Once again lets work backwards from the Cypher query and creation statements which roughly equate to the RDBMS counterparts originally shown and then discuss a few points.
// Num Raspberry Pi's bought by each customer
MATCH (o:Order)-[r:HAS_ORDER_ITEM]-(p:Product)
WHERE p.prodId = 'P4'
RETURN o.custId, sum(r.qty)
// Total number of distinct users who bought Raspberry Pi's
MATCH (o:Order)-[:HAS_ORDER_ITEM]-(p:Product)
WHERE p.prodId = 'P4'
RETURN count( distinct o.custId )
Hhhm, some aspects looks similar to SQL, and others very much not. The MATCH statement is obviously quite unique. The WHERE clause gives us a slightly warmer feeling of familiarity and RETURN looks (ish) like a SQL SELECT but slapped onto the end. There also appears to be some familiar looking count and distinct functions. So how does Neo4j model and create data for this scenario, and what does it look like under the covers?
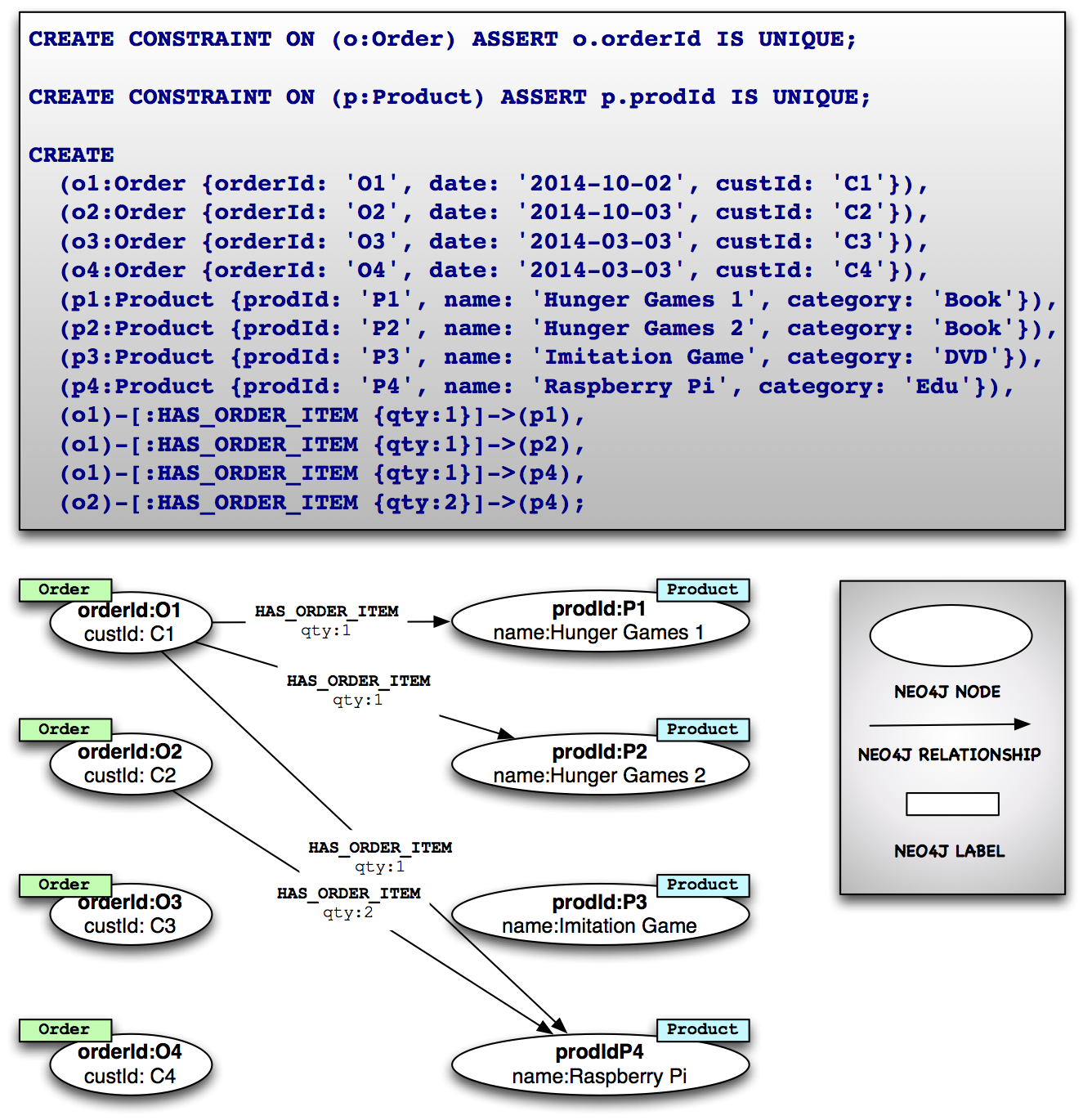
As with CQL, Neo4j also provides a shell whereby we can try out our queries and statements to gain some tabular insight into our data. We shall also be using this as shown in the diagrams below.
I should at this stage point out that Neo4j was a wonderful graph visualisation tool via the Neo4j console available for seeing visual “connections” however as we are comparing SQL, so we shall also use its shell program.
Eat on your lap – no table required
At its heart, Neo4j is a property based graph DB, consisting simply of nodes and relationships. Nodes of the same type can be grouped together using something called a “Label” – roughly equated to the way a table groups the same types of records in an RDBMS, except that there is no traditional schema per so – i.e. no restrictions on which properties (columns) the node (table ish) can contain. So in our example, although at present all of the Order nodes have three properties, this does not restrict us from adding another property, say a poNumber to new Order nodes created in the future – without affecting any of the previous ones. Neo4j is officially schema-optional as there are some forms of constraints (e.g. creating a genuinely unique key) and indexes which can be applied to your model. However, as far as defining for example that a User node will always have a name and an age attribute – that level of schema definition cannot be enforced out of the box at present.
Join the dots to make the connection …
Unlike Cassandra which goes for a denormalized approach, graphs are at the other end of the NoSQL spectrum. Being all about connected data, nodes are indeed able to be joined to each other and this is done via the first class Neo4j relationship concept. When it comes to querying or traversing the graph however, this joining is expressed rather as a pattern match. For example the generic “find me all orders with at least one product (orderItem)” is expressed in the ascii art syntax of MATCH (:Order)-[:HAS_ORDER_ITEM]-(:Product). In general with a graph you would typically look to constrain your query a bit more i.e. “find me all orders which contain the P4 product ” is expressed as:
MATCH (o:Order)-[:HAS_ORDER_ITEM]-(p:Product)
WHERE p.prodId = 'P4' return o.
Now this does look fundamentally different to any SQL you’ve seen. However, if you can get your head around the fact that the MATCH bits are “roughly” the join part, then the remaining syntax is more easily digested with things like WHERE clauses, count and distinct functions etc.
In an effort to make the Cypher language more “whiteboard friendly”, as well as try and expose and convey the underlying native graph structure inherent in the queries been undertaken, the Neo4j Cypher language designers explicitly opted for making pattern matching central, rather than opting for the more familiar, yet potentially more verbose standard SQL join like syntax. In order to help SQL thinkers jump this divide however, Neo4j provides a dedicated From SQL to Cypher section on the official Neo4j website.
Interestingly enough, OrientDB, which also operates in the graph (and document) database space have taken a slightly different stance. Disclaimer: I do not have commercial experience with OrientDB. From their website:
“… Instead of inventing “Yet Another Query Language”, we started from the widely used and well understood SQL. We then extended it to support more complex graph concepts like Trees and Graphs. Why SQL? SQL ubiquitous in the database developer world, it is familiar …” - [http://www.orientechnologies.com/docs/2.0/orientdb.wiki/Tutorial-SQL.html]http://www.orientechnologies.com/docs/2.0/orientdb.wiki/Tutorial-SQL.html
However in OrientDB’s version of SQL, as with Cypher, the choice was taken not to make use of the traditional SQL join syntax, instead opting for using a dot (.) notation[1] to navigate its relationships (referred to as links) instead. So even though its starting point is SQL, it too has chosen to deviate from using the standard SQL join syntax in order to better exploit the underlying data structure.
Conclusion
Via an analogy …
So you are a ‘box drawing expert’. You have however been using standard pens all your life for drawing boxes, and now you have been asked to draw a box using a new pen, which you are told, is specifically aimed at drawing boxes in a ‘new and shiny way’. So armed with your previous box drawing knowledge and experience, you set out on your task. Well how hard can it be you say. You know how to use a pen, you even have a trusted old favourite which you bring out for special occasions. This new pen probably just does some fancy highlighting or something, but at the end of the day if it looks like a pen, and writes like a pen, it’s probably still just a pen. You finish your box drawing exercise, and well, it does sort of look like the boxes you usually draw, maybe a little bit more messy than you were expecting, but hey, this must be how all the new kids are doing it, and it’s probably just what ‘new and shiny box world’ looks like.

Problem is, the pen you were given was actually a 3D doodling pen[2]. Yes it’s a sort of a pen, however it is not really meant for drawing in a 2D world, but rather a 3D one. Because however you were comfortable in applying your 2D way of thinking to the task at hand, you simply started by drawing your box in this mindset. If however, you understand that actually this 3D pen is capable of more than simply mimicking what can be done in a 2D world, your box may instead have turned out like this:

Via conventional words …
So yes, it appears some NoSQL vendors have “somewhat” adapted their querying languages, to a larger or lesser degree, to be more sympathetic towards some SQL like syntax and concepts. The fundamental differences in underlying data structures however, mean that this is never going to be a perfect fit and it is worth bearing this in mind when trying to use them.
Query languages and approaches to try and help people adapt/transition into new ways of thinking by comparing or making aspects of the query language seem familiar can be very helpful in some instances. However, as has been demonstrated in this blog, this can sometimes be confusing, especially if your background means you expect the semantics behind statements, and not merely the usage of common terminology, to operate in the same way as SQL. I would therefore urge caution in simply skimming the surface when engaging in these technologies and only thinking in your current (SQL) mindset, as you may fundamentally miss out on leveraging the best parts of your underlying datastore if you do, or even worse, design your model incorrectly in the first place as a result.
Can a language or database be all things to all people at the same time? Probably not. When it comes to trying to get to grips with a new kind of datastore, I feel that trying to gain some mechanical sympathy for your new datastore can go a long way to helping you understand it, as well as effectively being able to use it, regardless of what query language is being used; be that SQL like, a hybrid, or something completely different.
[1] OrientDB uses the “dot (.) notation” to navigate LINKS.” – https://github.com/orientechnologies/orientdb/wiki/SQL
[2] The 3D doodling pen is actually a real thing, and well it looks pretty impressive to be honest. Here is a link in case you are interested: http://www.makerstechnology.com/3doodler-3d-creativity-pen
Share this post
Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email